[javascript-jQuery] 정규식1(Regular Expressions)
본문
정규식(Regular Expressions)
정규식은 문자열에 포함된 문자 조합을 찾기 위해 사용되는 패턴입니다. 코드를 간략하게 만들 수 있으나, 가독성이 떨어질 수 있습니다.
RegExp의 exec, test 메소드와 String의 match, replace, search, split 메소드와 함께 사용됩니다.
1. 정규식
두가지 방법으로 정규식을 만들 수 있습니다.
정규식 패턴이 계속 지속될 경우
1 | var re = /ab+c/; |
정규식이 계속 지속 될 경우 위와 같은 리터럴 방법을 사용하는 것이 좋습니다.
정규식 패턴이 변경되는 경우
1 | var re = new RegExp("ab+c"); |
정규식 패턴이 바뀌는 경우, 생성자 함수를 사용하여 동적으로 정규식을 만들 수 있습니다.
2. 정규식 패턴 만들기
정규식 패턴은 /abc/와 같이 단순한 문자열로 만들 수 있습니다. 또한 /ab*c/ 또는 /(\d+)\.=d%/ 와 같이 특수 문자와 단순 문자열의 조합으로 정규식 패턴을 만들 수 있습니다.
단순 문자열 패턴
단순 문자열 패턴은 직접 찾고자 하는 문자들로 구성됩니다.
예를 들어, /abc/는 this is abc의 abc에 매칭됩니다.
1 | /abc/.exec("this is abc"); |
단순 문자열 패턴
하지만 /abc/는 this is ab c에 매칭 되지 않습니다.
1 | /abc/.exec("this is ab c"); |
단순 문자열 패턴
특수문자를 사용한 패턴
하나 이상의 b를 찾거나, 단순 문자열 패턴보다 다양한 문자열을 찾기 위해 사용됩니다.
예를 들어, /ab*c/ 패턴은 'a' 뒤에 0개 이상의 'b'와 바로 뒤에 'c'가 있는 문자열을 찾습니다. /ab*c/는 abbbbbbbbbce에서 abbbbbbbbbc와 매칭됩니다.
1 | /ab*c/.exec("this is abbbbbbbbbce"); |
특수 문자를 사용한 패턴
정규식에서의 특수문자
문자 | 의미 | ||||
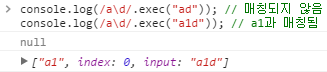
\ | 1. 단순문자 앞에 \단순문자 앞에 \는 앞에 있는 단순문자를 단순문자로 해석되지 않고, 다른 의미로 해석되어집니다. /a\d/는 단순 ad와 매칭되지 않습니다. \d는 새로운 의미를 가지게 됩니다. (\d는 0부터 9까지의 숫자와 매칭됩니다.)
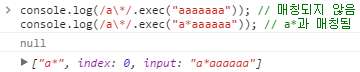
2. 특수문자 앞에 \특수문자 앞에 \는 앞에 있는 특수문자를 단순문자로 해석합니다. /a\*/는 aaaaaaa와 매칭되지 않습니다. \*은 단순문자 *로 해석됩니다. (특수문자 *은 앞 문자가 0개 이상일 경우 매칭됩니다.)
| ||||
^ | 입력의 시작 문자열에 매칭됩니다. Multi-line 플래그가 참으로 설정되어 있다면, 줄 바꿈 문자 바로 다음 문자에도 매칭됩니다. /^A/는 "an A"와 매칭되지 않습니다. 하지만 "An E"와는 첫번째 'A'와 매칭됩니다.
^는 문자셋([abc]) 패턴의 첫글자로 쓰인다면, 다른 의미를 가집니다. ([^abc]는 위에 언급한 내용되 다른 의미를 가짐) | ||||
$ | 입력의 끝 문자열에 매칭됩니다. Multi-line 플래그가 참으로 설정되어 있다면, 줄 바꿈 문자 바로 전 문자에도 매칭됩니다. /$t/는 eater에 매칭되지 않지만, eat의 마지막 문자 t에 매칭됩니다.
| ||||
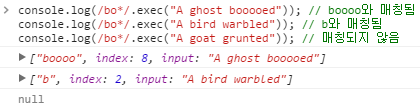
* | 0번 이상 반복되는 문자열에 매칭됩니다. {0, }와 동일합니다. /bo*/은 "A ghost booooed"의 "boooo"과 매칭됩니다. /bo*/은 "A bird warbled"의 'b'에 매칭됩니다. 하지만, /bo*/은 "A goat grunted"와는 매칭되지 않습니다.
/o*/은 "abcd"와 동일한 문자를 가지고 있지 않습니다. 하지만, 특수문자 *의 의미는 0번 이상 반복되는 문자열에 매칭되기 때문에, 동일한 문자가 없더라도 매칭되는 결과를 확인 할 수 있습니다.
| ||||
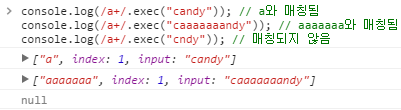
+ | 1번 이상 반복되는 문자열에 매칭됩니다. {1, }과 동일합니다. /a+/는 "candy"의 'a'에 매칭됩니다. /a+/는 "caaaaaaandy"의 "aaaaaaa"와 매칭됩니다. 하지만, /a+/는 "cndy"와는 매칭되지 않습니다.
| ||||
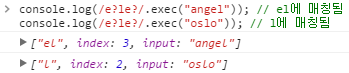
? | 0~1번 반복되는 문자열에 매칭됩니다. {0, 1}과 동일합니다. /e?le?/은 'e'가 0~1번 반복 후, 'l'이 온후 'e'가 0~번 반복된 문자열을 찾습니다. /e?le?/은 "angel"의 "el"에 매칭됩니다. /e?le?/은 "oslo"의 'l'에 매칭됩니다.
*, +, ?, {} 패턴은 가능 한 많은 문자열을 매칭시킵니다. *, +, ?, {} 패턴 뒤에 ? 패턴을 사용하면, 가능한 가장 적은 문자열을 매칭시킵니다. /\d+/는 "123abc"에 "123"과 매칭됩니다. 하지만, /\d+?/의 경우는 "123abc"에 '1'과만 매칭됩니다.
x(?=y)와 x(!?y)와 같이 검증에서도 사용됩니다. | ||||
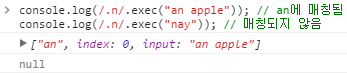
. | 다음 줄 문자(개행 문자)를 제외한 문자열에 매칭됩니다. /.n/은 "an apple"에 "an"에 매칭됩니다. 하지만 /.n/은 "nay"와는 매칭되지 않습니다.
| ||||
(x) | 'x'에 일치하고 일치한 것을 기억합니다. 괄호는 포획 괄호(capturing parentheses)라고 합니다. /(foo) (bar)/은 "foo bar test"의 "foo bar"에 매칭됩니다. 또한 () 패턴으로 매칭된 값이 기억되는 것을 확인 할 수 있습니다.
| ||||
(?:x) | 'x'에 일치하지만 일치한 것을 기억하지 않습니다. 괄호는 비포획 괄호(non-capturing parentheses)라고 합니다. /abc+/는 "abcabcabc"에 "abc"가 매칭됩니다. ('ab' 뒤에 오는 'c'의 1번 이상 반복되는 문자열을 매칭합니다.) abc가 반복되는 것을 매칭하고 싶을 때 (?:x) 패턴을 사용할 수 있습니다. /(?:abc)+/는 "abcabcabc"에 "abcabcabc"가 매칭됩니다. (abc 전체를 + 패턴으로 매칭하게 됩니다.)
| ||||
x(?=y) | 'y'가 뒤따라오는 'x'에만 매칭됩니다. lookahead라고 불립니다. /foo(?=bar)/는 "foobar"의 "foo"에 매칭됩니다. /foo(?=bar|test)/는 "footest"의 "foo"에 매칭됩니다. (foo이 뒤따라오는 문자열이 bar 또는 test 일 경우 매칭됩니다.)
| ||||
x(?!y) | 'y'가 뒤따라 오지 않는 'x'에만 매칭됩니다. negated lookahead라고 불립니다. /\d+(?!\.)/는 "3.141"에 "141"과 매칭됩니다. (소수점이 뒤따라오지 않는 숫자와 매칭됩니다.)
| ||||
x|y | 'x' 또는 'y'에 일치합니다. /green|red/는 "green apple"의 "green"에 매칭됩니다. /green|red/는 "red apple"의 "red"에 매칭됩니다.
| ||||
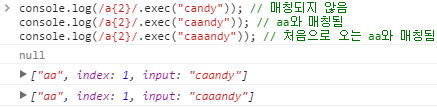
{n} | 앞 문자가 n번 나타날 경우 매칭됩니다. (n은 양의 정수) /a{2}/는 "candy"에는 매칭되지 않습니다. /a{2}/는 "caandy"의 "aa"와 매칭됩니다. /a{2}/는 "caaandy"는 처음으로 오는 "aa"와 매칭됩니다.
| ||||
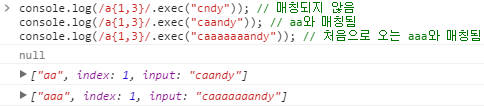
{n,m} | n ~ m번 반복되는 문자열과 매칭됩니다. (m, m은 양의 정수, n <= m) /a{1, 3}/는 "cndy"에는 매칭되지 않습니다. /a{1, 3}/는 "caandy"의 "aa"와 매칭됩니다. /a{1, 3}/는 "caaaaaaandy"의 처음으로 오는 "aaa"에 매칭됩니다.
| ||||
[xyz] | 문자셋(Character set)을 말합니다. 점(.), 별표(*)와 같은 특수 문자는 문자셋에서는 단순 문자로 인식됩니다. 하이픈(-)을 이용하여 문자의 범위를 지정 할 수 있습니다. /[a-d]/는 "brisket"의 'b'와 매칭됩니다. /[a-z.]+/는 "test.i.ng"의 문자열 전체, "test.i.ng"과 매칭됩니다.
| ||||
[^xyz] | 음의 문자셋(negated character set) 또는 보수 문자셋(complemented character set)을 말합니다. [] 안에 있지 않은 문자열과 매칭됩니다. 문자셋과 동일하게 하이픈(-)을 이용하여 문자의 번위를 저정 할 수 있습니다. /[^a-d]/는 "brisket"에서 처음으로 a부터 d까지의 문자에 포함되지 않는 'r'과 매칭됩니다. /[^a-d]/는 "chop"의 'h'와 매칭됩니다.
| ||||
[\b] | 백스페이스와 매칭됩니다. 백스페이스 문자에 일치 시키려면 대괄호([])를 이용해야 합니다. | ||||
\b | 단어의 경계를 말합니다. /\bm/은 "moon"의 m과 매칭됩니다. /oo\b/는 "moon"과 매칭되지 않습니다. (문자열의 끝이 o이 아니지 때문에) /n\b/는 "moon"의 n과 매칭됩니다.
| ||||
\B | 단어의 경계가 아닌 곳을 말합니다. /\B../은 "noonday"의 "oo"와 매칭됩니다.
| ||||
\cX | X는 A에서 Z까지 문자중 하나입니다. 문자열에서 컬트롤 문자와 매칭됩니다. | ||||
\d | 숫자 문자와 매칭됩니다. /\d"/는 "a1b"의 '1'에 매칭됩니다.
| ||||
\D | 숫자가 아닌 문자와 매칭됩니다. ([^0-9]와 동일) /\D/는 "1a2"의 'a'에 매칭됩니다.
| ||||
\f | 폼피드(U+000C) 문자에 매칭됩니다. | ||||
\n | 줄 바꿈(U+000A) 문자에 매칭됩니다. | ||||
\r | 캐리지 리턴(U+000D) 문자에 매칭됩니다. | ||||
\s | 스페이스, 탭, 폼피드, 불 바꿈 문자등을 포함한 하나의 공백 문자와 매칭됩니다. ([ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000] 와 동일) /\sbar/는 "foo bar"의 " bar"에 매칭됩니다.
| ||||
\S | 공백이 아닌 하나의 문자와 매칭됩니다. ([^ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000] 와 동일) /\S+/는 "foo bar"의 "foo"에 매칭됩니다. (가장 먼저 오는 공백아닌 문자열)
| ||||
\t | 탭(U+0009) 문자에 매칭됩니다. | ||||
\v | 수직 탭(U+000B) 문자에 매칭됩니다. | ||||
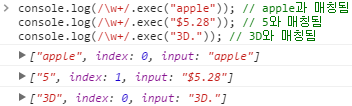
\w | 밑줄 문자를 포함한 영어, 숫자 문자에 매칭됩니다. ([A-Za-z0-9_] 와 동일) /\w+/는 "apple"에 문자열 전체, "apple"과 매칭됩니다. /\w+/는 "$5.28"에 '5'와 매칭됩니다. /\w+/는 "3D."에 "3D"와 매칭됩니다.
| ||||
\W | 단어가 아닌 문자와 매칭됩니다. ([^A-Za-z0-9_] 와 동일) /\W+/는 "3D."에 '.'과 매칭됩니다.
| ||||







![특수문자 [xyz] 패턴](http://cfile23.uf.tistory.com/image/222D743A589985B734048F)
![특수문자 [^xyz] 패턴](http://cfile29.uf.tistory.com/image/25202947589988690B7CDD)

댓글목록 0